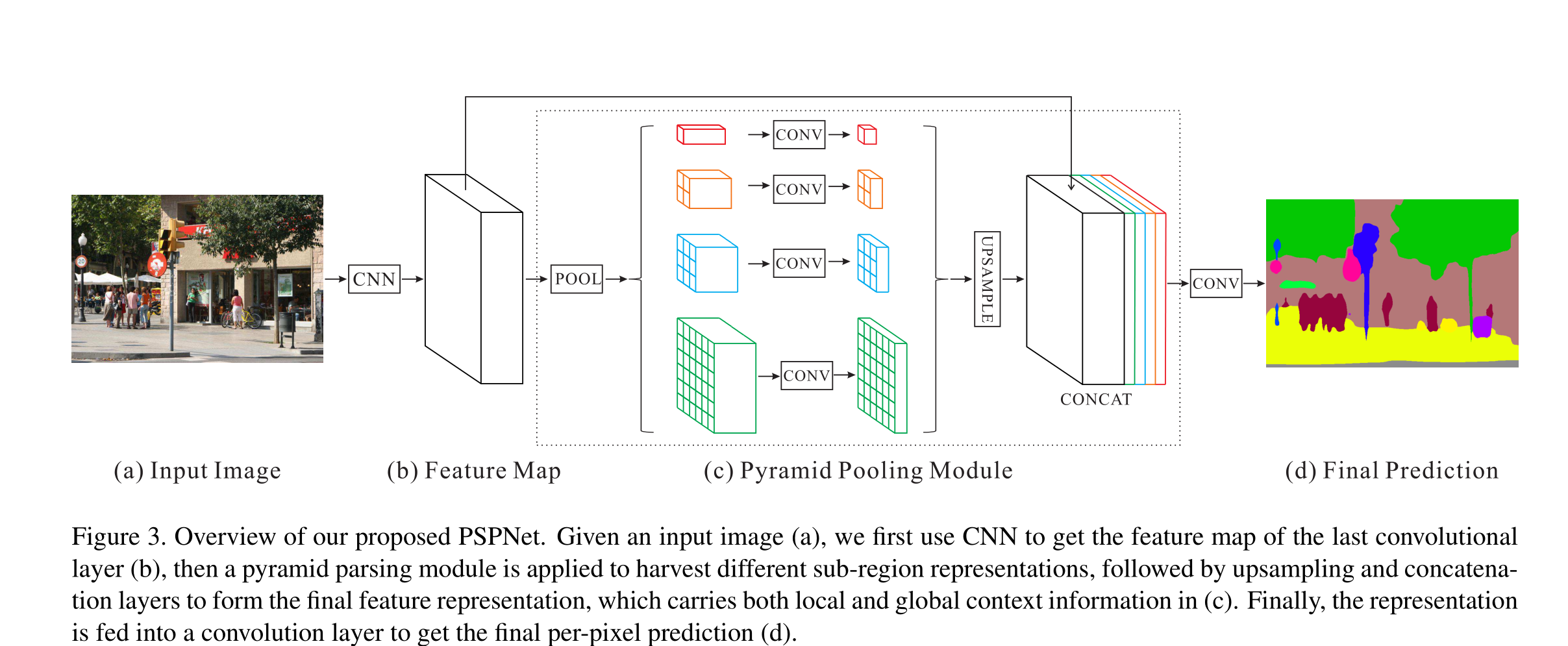
目录
什么是Apache Drill?
Apache Drill的主要特点是什么?
Apache Drill如何实现对复杂数据的查询?
描述Apache Drill的数据存储模型。
为什么Apache Drill被称为自服务的SQL查询引擎?
Apache Drill支持哪些类型的数据源?
解释Apache Drill中的“schema discovery”功能。
如何在Apache Drill中创建一个新的数据源?
Apache Drill如何处理大规模数据集的查询性能?
什么是Apache Drill的执行计划?
在Apache Drill中,如何优化查询性能?
Apache Drill的分片(sharding)和复制(replication)策略是什么?
解释Apache Drill中的“动态发现”机制。
Apache Drill如何确保数据安全性和隐私?
如何在Apache Drill中实现数据的实时查询?
如何在本地环境中安装Apache Drill?
下载与解压
设置环境变量
启动Drill
测试Drill
Apache Drill的配置文件包含哪些主要部分?
如何配置Apache Drill以支持多数据源?
解释Apache Drill的集群模式与单节点模式的区别。
集群模式
单节点模式
如何在Apache Drill中设置资源限制?
如何在Apache Drill中启用日志记录?
Apache Drill的故障恢复机制是什么?
如何在Apache Drill中配置安全性,如SSL/TLS?
如何在Apache Drill中配置用户认证和授权?
如何在Apache Drill中管理元数据?
如何在Apache Drill中编写基本的SQL查询语句?
Apache Drill支持哪些SQL标准?
如何在Apache Drill中使用JOIN操作?
如何在Apache Drill中使用窗口函数?
如何在Apache Drill中处理分区数据?
如何在Apache Drill中进行聚合查询?
如何在Apache Drill中使用子查询?
如何在Apache Drill中优化查询性能?
Apache Drill中的查询优化器如何工作?
如何在Apache Drill中使用索引提高查询效率?
如何在Apache Drill中处理大数据量的排序操作?
如何在Apache Drill中进行数据预加载以加速查询?
如何在Apache Drill中使用缓存机制?
如何在Apache Drill中调试和优化慢查询?
如何在Apache Drill中使用UDF(用户定义函数)?
如何在Apache Drill中实现流式数据处理?
Apache Drill如何与其他大数据工具(如Hadoop、Spark)集成?
如何在Apache Drill中实现跨数据源查询?
如何在Apache Drill中使用JSON、CSV等非结构化数据?
Apache Drill如何处理半结构化数据?
如何在Apache Drill中实现数据湖查询?
Apache Drill在企业级应用中的部署策略是什么?
如何在Apache Drill中实现数据仓库的功能?
如何在Apache Drill中实现数据治理和数据质量控制?
如何在Apache Drill中实现数据可视化和报告?
如何在Apache Drill中识别和解决常见的查询错误?
如何在Apache Drill中处理数据倾斜问题?
如何在Apache Drill中避免数据扫描的性能瓶颈?
如何在Apache Drill中处理内存溢出问题?
如何在Apache Drill中监控系统性能?
如何在Apache Drill中实现高可用性?
如何在Apache Drill中备份和恢复数据?
如何在Apache Drill中实施数据生命周期管理?
如何在Apache Drill中维护数据一致性?
如何在Apache Drill中遵循数据合规性和法规要求?
什么是Apache Drill?
Apache Drill是一个开源的分布式SQL查询引擎,设计用于提供对大规模、复杂数据集的低延迟查询能力。它最显著的特点是能够直接查询和分析海量的半结构化、非结构化以及结构化数据,而无需事先定义固定的模式(schema)。这使得Apache Drill成为处理数据湖和大数据分析的理想选择,因为它可以灵活地适应各种数据格式,包括JSON、Avro、Parquet、CSV等,并且能够跨多个数据源进行查询。
Apache Drill的主要特点是什么?
Apache Drill拥有多个关键特性,使其在大数据查询领域独树一帜:
- Schema-less查询:Drill能够在没有预定义模式的情况下读取和查询数据,这大大简化了数据的摄入和查询过程。
- 动态数据发现:Drill能够自动检测数据的结构,即所谓的“schema discovery”,这意味着用户可以直接查询数据而无需手动创建表定义。
- 分布式处理:Drill的设计支持分布式环境,能够利用集群中的多节点并行处理数据